
Vlookup 是我們很常使用的 Excel 功能,他幫我們達成快速匹配數值,當我們需要找到 A 所對應的 B 值時,這項功能就會非常好用。就如同上篇文章展示的一些常見的 Excel 任務,用 Vlookup 來做模糊字符串匹配,以顯示這個過程,本章節要來介紹的是 Python 版本的 Vlookup:FuzzyWuzzy。
讓我們嘗試在數據集中添加一個州的縮寫。從Excel的角度來看,最簡單的方法可能是添加一個新的列,對州名做一個vlookup,然後填上縮寫。比如說 Texas =TX,有一些數值沒有正確顯示出來。這是因為我們把一些狀態拼錯了。在Excel中處理這個問題將是非常具有挑戰性的(在大數據集上)。
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
state_to_code = {"VERMONT": "VT", "GEORGIA": "GA", "IOWA": "IA", "Armed Forces Pacific": "AP", "GUAM": "GU","KANSAS": "KS", "FLORIDA": "FL", "AMERICAN SAMOA": "AS", "NORTH CAROLINA": "NC", "HAWAII": "HI","NEW YORK": "NY", "CALIFORNIA": "CA", "ALABAMA": "AL", "IDAHO": "ID", "FEDERATED STATES OF MICRONESIA": "FM","Armed Forces Americas": "AA", "DELAWARE": "DE", "ALASKA": "AK", "ILLINOIS": "IL","Armed Forces Africa": "AE", "SOUTH DAKOTA": "SD", "CONNECTICUT": "CT", "MONTANA": "MT", "MASSACHUSETTS": "MA", "PUERTO RICO": "PR", "Armed Forces Canada": "AE", "NEW HAMPSHIRE": "NH", "MARYLAND": "MD", "NEW MEXICO": "NM","MISSISSIPPI": "MS", "TENNESSEE": "TN", "PALAU": "PW", "COLORADO": "CO", "Armed Forces Middle East": "AE","NEW JERSEY": "NJ", "UTAH": "UT", "MICHIGAN": "MI", "WEST VIRGINIA": "WV", "WASHINGTON": "WA","MINNESOTA": "MN", "OREGON": "OR", "VIRGINIA": "VA", "VIRGIN ISLANDS": "VI", "MARSHALL ISLANDS": "MH","WYOMING": "WY", "OHIO": "OH", "SOUTH CAROLINA": "SC", "INDIANA": "IN", "NEVADA": "NV", "LOUISIANA": "LA","NORTHERN MARIANA ISLANDS": "MP", "NEBRASKA": "NE", "ARIZONA": "AZ", "WISCONSIN": "WI", "NORTH DAKOTA": "ND","Armed Forces Europe": "AE", "PENNSYLVANIA": "PA", "OKLAHOMA": "OK", "KENTUCKY": "KY", "RHODE ISLAND": "RI","DISTRICT OF COLUMBIA": "DC", "ARKANSAS": "AR", "MISSOURI": "MO", "TEXAS": "TX", "MAINE": "ME"}
scorer 計算兩個字串相似度的函式,預設fuzz.WRatio()。 limit是輸出個數。輸出為陣列,元素為元組,元組第一個匹配到的字串,第二個為int型,為score。對輸出按照score排序。score_cutoff為一個閾值,當score小於該閾值時,不會輸出。返回一個生成器,輸出每個大於 score_cutoff的匹配,按順序輸出不排序,以下面為例 95 就是他的 scorer 分數。
process.extractOne("Minnesotta",choices=state_to_code.keys())
process.extractOne("AlaBAMMazzz",choices=state_to_code.keys())
('MINNESOTA', 95)
('ALABAMA', 78)
現在我們知道了這是如何工作的,我們創建我們的函數,以獲取狀態列並將其轉換為有效的縮略語。我們對這個數據使用80 score_cutoff。你可以玩一玩,看看哪個數字適合你的數據。你會注意到,我們要么返回一個有效的縮寫,要么返回一個np.nan,這樣我們在字段中就有一些有效的值。
def convert_state(row):
if pd.notnull(row['state']):
abbrev = process.extractOne(row["state"],choices=state_to_code.keys(),score_cutoff=80)
if abbrev:
return state_to_code[abbrev[0]]
return np.nan
df_final.insert(6, "abbrev", np.nan)
df_final['abbrev'] = df_final.apply(convert_state, axis=1)
df_final.tail()

我們按州獲得一些小計。在Excel中我們將使用小計工具為我們做這個。
df_sub=df_final[["abbrev","Jan","Feb","Mar","total"]].groupby('abbrev').sum()
df_sub
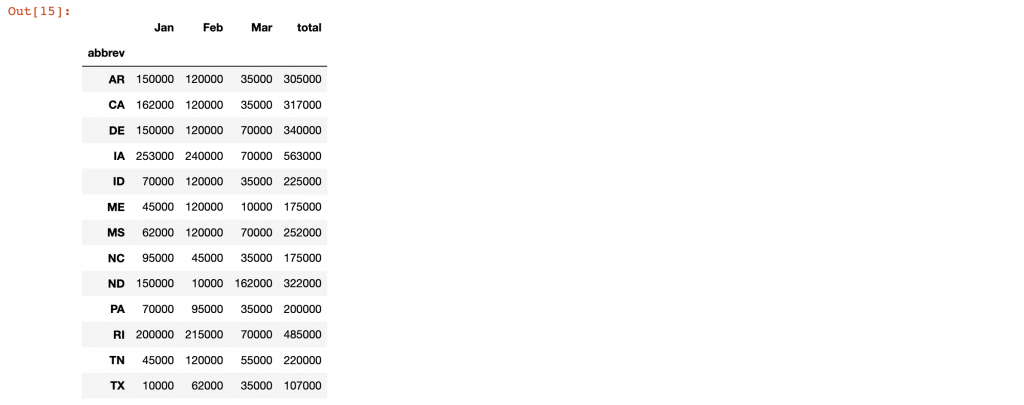
或者是說我們也可以預設符號,使用$符號搭配 .Format() 函數
def money(x):
return "${:,.0f}".format(x)
formatted_df = df_sub.applymap(money)
formatted_df

這些方式就是利用 FuzzyWuzzy 來取代 Vlookup 使用的解決方法,FuzzyWuzzy 給我們帶來了非常多元的應用方法,我們也可以更彈性的把字詞加入到字典中,協助我更容易使用 Python 來處理試算表。
今年沒組團,每一筆一字矢志不渝的獻身精神都是為歷史書寫下新頁,有空的話可以走走逛逛我們去年寫的文章。
Jerry 據說是個僅佔人口的 4% 人口的 INFP 理想主義者,總是從最壞的生活中尋找最好的一面,想方設法讓世界更好,內心的火焰和熱情可以光芒四射,畢業後把人生暫停了半年,緩下腳步的同時找了份跨領域工作。偶而散步、愛跟小動物玩耍。曾立過很多志,最近是希望當一個有夢想的人。
謝謝你的時間「訂閱,追蹤和留言」都是陪伴我走過 30 天鐵人賽的精神糧食。

 iThome鐵人賽
iThome鐵人賽